Nebula 的博客
Nebula 的博客1. 介绍js的基本数据类型
TIP
undefinednullBooleanNumberStringSymbol(创建后独一无二且不可变的数据类型,解决全局变量的问题)BigInt(数字类型的数据,可以表示任意精度格式的整数)
2. js 有几种类型的值
TIP
- 栈: 原始数据类型(undefined、null、Boolean、Number、String)
- 堆: 引用数据类型(对象、数组、函数)
3. 内部属性 [[Class]] 是什么 (Object.prototype.soString.call())
TIP
所有 typeof 返回值为 "object" 的对象(如数组)都包含一个内部属性 [[Class]](我们可以把它看作一个内部的分类,而非 传统的面向对象意义上的类)。这个属性无法直接访问,一般通过 Object.prototype.toString(..) 来查看
Object.prototype.toString.call()
4. 介绍 js 有哪些内置对象
TIP
全局的对象( global objects )或称标准内置对象
- 值属性:这些全局属性返回一个简单值,没有自己的属性和方法
InfinityNaNundefinednull字面量 - 函数属性:全局函数可以直接调用,不需要再调用时指定所属对象,执行结束后会将结果直接返回给调用者
eval()parseFloat()parseInt() - 基本对象,基本对象是定义或使用其他对象的基础。基本对象包括一般对象、函数对象和错误对象。
例如 Object、Function、Boolean、Symbol、Error 等
- 数字和日期对象,用来表示数字、日期和执行数学计算的对象。
例如 Number、Math、Date
- 字符串,用来表示和操作字符串的对象。
例如 String、RegExp 6. 可索引的集合对象,这些对象表示按照索引值来排序的数据集合,包括数组和类型数组,以及类数组结构的对象。例如 Array
- 使用键的集合对象,这些集合对象在存储数据时会使用到键,支持按照插入顺序来迭代元素。
例如 Map、Set、WeakMap、WeakSet
- 矢量集合,SIMD 矢量集合中的数据会被组织为一个数据序列。
例如 SIMD 等
- 结构化数据,这些对象用来表示和操作结构化的缓冲区数据,或使用 JSON 编码的数据。
例如 JSON 等
- 控制抽象对象
例如 Promise、Generator 等
- 反射
例如 Reflect、Proxy
- 国际化,为了支持多语言处理而加入 ECMAScript 的对象。
例如 Intl、Intl.Collator 等
WebAssembly
其他
例如 arguments
5. null 和 undefined 的区别
TIP
Undefined和Null都是基本数据类型undefined代表的含义是未定义,null代表的含义是空对象。一般变量声明了但还没有定义的时候会返回undefined,null主要用于赋值给一些可能会返回对象的变量,作为初始化。undefined在 js 中不是一个保留字,这意味着我们可以使用undefined来作为一个变量名,这样的做法是非常危险的,它会影响我们对undefined值的判断。但是我们可以通过一些方法获得安全的undefined值,比如说void 0- 当我们对两种类型使用
typeof进行判断的时候,Null类型化会返回“object”,这是一个历史遗留的问题。当我们使用双等号对两种类型的值进行比较时会返回 true,使用三个等号时会返回 false。
typeof null // 'object'
typeof undefined // 'undefined'
null == undefined // true
null === undefined // false
// 使用 void 0 来获取安全的 undefined
6. JavaScript 原型,原型链?有什么特点?
TIP
在 js 中我们是使用构造函数来新建一个对象的,每一个构造函数的内部都有一个 prototype 属性值,这个属性值是一个对 象,这个对象包含了可以由该构造函数的所有实例共享的属性和方法。当我们使用构造函数新建一个对象后,在这个对象的内部 将包含一个指针,这个指针指向构造函数的 prototype 属性对应的值,在 ES5 中这个指针被称为对象的原型。一般来说我们 是不应该能够获取到这个值的,但是现在浏览器中都实现了 proto 属性来让我们访问这个属性,但是我们最好不要使用这 个属性,因为它不是规范中规定的。ES5 中新增了一个 Object.getPrototypeOf() 方法,我们可以通过这个方法来获取对 象的原型。
当我们访问一个对象的属性时,如果这个对象内部不存在这个属性,那么它就会去它的原型对象里找这个属性,这个原型对象又 会有自己的原型,于是就这样一直找下去,也就是原型链的概念。原型链的尽头一般来说都是 Object.prototype 所以这就 是我们新建的对象为什么能够使用 toString() 等方法的原因。
特点:
JavaScript 对象是通过引用来传递的,我们创建的每个新对象实体中并没有一份属于自己的原型副本。当我们修改原型时,与 之相关的对象也会继承这一改变。
7. js 获取原型的方法?
TIP
- p.proto
- p.constructor.prototype
- Object.getPrototypeOf(p)
8. typeof NaN 的结果是什么? 'number'
TIP
typeof NAN // 'number'
NaN 是一个特殊值,它和自身不相等,是唯一一个非自反(自反,reflexive,即 x === x 不成立)的值。而 NaN != NaN 为 true
9. 如何将浮点数点左边的数每三位添加一个逗号,如 12000000.11 转化为『12,000,000.11』?
TIP
// 方法一
function format(number) {
return number && number.replace(/(?!^)(?=(\d{3})+\.)/g, ",");
}
// 方法二
function format1(number) {
return Intl.NumberFormat().format(number)
}
// 方法三
function format2(number) {
return number.toLocaleString('en')
}
10. 什么是闭包,为什么要用它?
TIP
闭包是指有权访问另一个函数作用域中变量的函数,创建闭包的最常见的方式就是在一个函数内创建另一个函数,创建的函数可以访问到当前函数的局部变量。
闭包有两个常用的用途。
闭包的第一个用途是使我们在函数外部能够访问到函数内部的变量。通过使用闭包,我们可以通过在外部调用闭包函数,从而在外部访问到函数内部的变量,可以使用这种方法来创建私有变量。
函数的另一个用途是使已经运行结束的函数上下文中的变量对象继续留在内存中,因为闭包函数保留了这个变量对象的引用,所以这个变量对象不会被回收。
其实闭包的本质就是作用域链的一个特殊的应用,只要了解了作用域链的创建过程,就能够理解闭包的实现原理。
11. new 操作符具体干了什么呢?如何实现?
TIP
- 首先创建了一个新的空对象
- 设置原型,将对象的原型设置为函数的
prototype对象 - 让函数的
this指向这个对象,执行构造函数的代码(为这个新对象添加属性) - 判断函数的返回值类型,如果是值类型,返回创建的对象。如果是引用类型,返回这个引用类型的对象
function objectFactory() {
let newObject = null,
constructor = Array.prototype.shift.call(arguments),
result = null;
// 参数判断
if (typeof constructor !== "function") {
console.error("type error");
return;
}
// 新建一个空对象,对象的原型为构造函数的 prototype 对象
newObject = Object.create(constructor.prototype);
// 将 this 指向新建对象,并执行函数
result = constructor.apply(newObject, arguments);
// 判断返回对象
let flag =
result && (typeof result === "object" || typeof result === "function");
// 判断返回结果
return flag ? result : newObject;
}
// 使用方法
// objectFactory(构造函数, 初始化参数);
12. 执行对象查找时,排除查找原型的方法?hasOwnProperty
TIP
hasOwnProperty
所有继承了 Object 的对象都会继承到 hasOwnProperty 方法。这个方法可以用来检测一个对象是否含有特定的自身属性,和 in 运算符不同,该方法会忽略掉那些从原型链上继承到的属性。
13. js 延迟加载的方式
TIP
defer属性:(让脚本的加载与文档的解析同步解析,然后在文档解析完成后再执行这个脚本文件,这样的话就能使页面的渲染不被阻塞。多个设置了 defer 属性的脚本按规范来说最后是顺序执行的,但是在一些浏览器中可能不是这样)async属性: (会使脚本异步加载,不会阻塞页面的解析过程,但是当脚本加载完成后立即执行 js 脚本,这个时候如果文档没有解析完成的话同样会阻塞。多个 async 属性的脚本的执行顺序是不可预测的,一般不会按照代码的顺序依次执行)- 动态创建
DOM方式:(对文档的加载事件进行监听,当文档加载完成后再动态的创建 script 标签来引入 js 脚本) - 使用
setTimeout延迟方法 - 让
js最后执行: (将 js 脚本放在文档的底部,来使 js 脚本尽可能的在最后来加载执行)
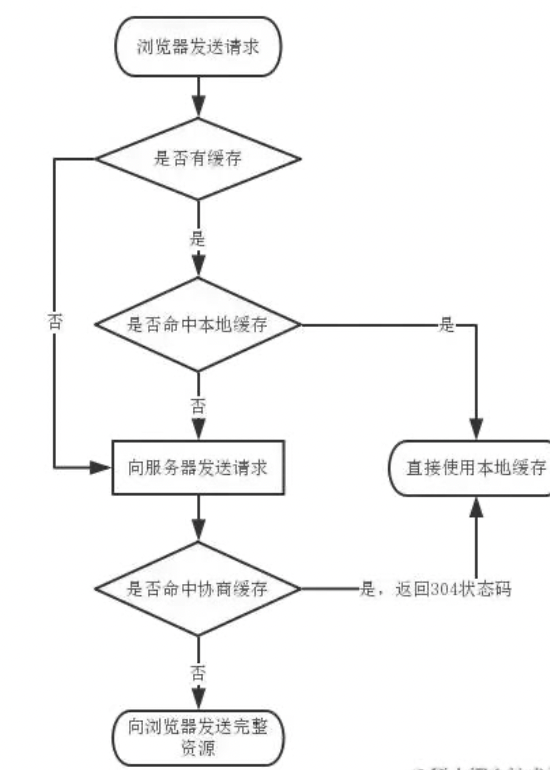
14. js 的缓存机制
浏览器缓存分为
协商缓存和强缓存
强缓存: 主要使用 Expires 和 Cache-Control 两个字段,同时存在 后者优先级更高。当命中强缓存时候,客户端不会再去请求,直接从缓存中读取内容,并返回 HTTP 状态码 200
TIP
强缓存:
Expires :
响应头,代表该资源的过期时间,是一个 GMT 格式的标准时间
当客户端请求服务器的时候,服务器会返回资源的同时还会带上响应头Expires,表示资源的过期具体时间,如果客户端在过期时间之前再次获取该资源,就不需要再请求我服务器了,可以直接在缓存里面拿。
在过期时间以内,为用户省了很多流量
减少了服务器重复读取磁盘文件的压力
缓存过期后,服务器不管文件有没有变化都会再次请求服务器
缓存过期时间是一个具体的时间,这个时间依赖于客户端的时间,如果时间不准确或者被改动缓存也会收到影响
Cache-Control:
请求/响应头,缓存控制字段,精确控制缓存策略
为了让强缓存更精确,HTTP1.1增加了Cache-Control字段。Cache-Control既能出现在请求头又能出现在响应头,其不同的值代表不同的意思,下面我们具体分析一下。
服务器端参数:
max-age: 在多少秒内有效,是一个相对时间,这样比Expires具体的时间就更精确了s-maxage: 就是用于表示cache服务器上(比如 cache CDN,缓存代理服务器)的缓存的有效时间的,并只对public缓存有效no-cache: 不使用本地强缓存。需要使用缓存协商no-store: 直接禁止浏览器缓存数据,每次用户请求该资源,都会向服务器发送一个请求,每次都会下载完整的资源public: 可以被所有的用户缓存,包括终端用户和中间代理服务器private: 只能被终端用户的浏览器缓存,不允许中间缓存代理进行缓存,默认的
客户端参数:
max-stale: 5: 表示客户端到代理服务器上拿缓存的时候,即使代理缓存过期了也不要紧,只要过期时间在 5 秒之内,还是可以从代理中获取的min-fresh: 5: 表示代理缓存需要一定的新鲜度,不要等到缓存刚好到期再拿,一定要在到期前 5 秒之前的时间拿,否则拿不到only-if-cached: 这个字段加上后表示客户端只会接受代理缓存,而不会接受源服务器的响应。如果代理缓存无效,则直接返回 504(Gateway Timeout)
TIP
协商缓存:
协商缓存主要有四个头字段,它们两两组合配合使用,
If-Modified-Since和Last-Modified一组,Etag和If-None-Match一组,当同时存在的时候会以Etag和If-None-Match为主。当命中协商缓存的时候,服务器会返回HTTP状态码304,让客户端直接从本地缓存里面读取文件。
If-Modified-Since: 请求头,资源最近修改时间,由浏览器告诉服务器。其实就是第一次访问服务端返回的Last-Modified的值Last-Modified: 响应头,资源最近修改时间,由服务器告诉浏览器Etag: 响应头,资源标识,由服务器告诉浏览器If-None-Match: 请求头,缓存资源标识,由浏览器告诉服务器。其实就是第一次访问服务端返回的Etag的值
TIP
缓存的配置:
location / {
# 其它配置
...
if ($request_uri ~* .*[.](js|css|map|jpg|png|svg|ico)$) {
#非html缓存1个月
add_header Cache-Control "public, max-age=2592000";
}
if ($request_filename ~* ^.*[.](html|htm)$) {
#html文件使用协商缓存
add_header Cache-Control "public, no-cache";
}
}
15. 防抖(n秒内多次触发,重新计时) 、节流(n秒内多次触发,只执行一次)
TIP
函数防抖:在事件被触发 n 秒后再执行回调,如果在这 n 秒内事件又被触发,则重新计时。
函数节流:规定一个单位时间,在这个单位时间内,只能有一次触发事件的回调函数执行,如果在同一个单位时间内某事件被触发多次,只有一次能生效。
函数防抖是指在事件被触发 n 秒后再执行回调,如果在这 n 秒内事件又被触发,则重新计时。这可以使用在一些点击请求的事件上,避免因为用户的多次点击向后端发送多次请求。
函数节流是指规定一个单位时间,在这个单位时间内,只能有一次触发事件的回调函数执行,如果在同一个单位时间内某事件被触发多次,只有一次能生效。节流可以使用在 scroll 函数的事件监听上,通过事件节流来降低事件调用的频率。
// 防抖:
function debounce(fn, wait) {
let timer = null
return function() {
const context = this
const args = arguments
// 如果此时存在定时器的话,则取消之前的定时器重新计时
if(timer) {
clearTimeout(timer)
timer = null
}
// 设置定时器,使事件间隔指定事件后执行
timer = setTimeout(() => {
fn.apply(context, args)
}, wait)
}
}
// 节流
function throttle(fn, delay) {
const preTime = Date.now()
return function() {
const context = this
const args = arguments
const nowTime = Date.now()
// 如果两次事件间隔超过了指定时间,则执行函数
if(nowTime - preTime >= delay) {
preTime = Date.now()
return fn.apply(context, args)
}
}
}
16. js 中的深浅拷贝实现?
TIP
// 浅拷贝的实现;
function shallowCopy(object) {
// 只拷贝对象
if (!object || typeof object !== "object") return;
// 根据 object 的类型判断是新建一个数组还是对象
let newObject = Array.isArray(object) ? [] : {};
// 遍历 object,并且判断是 object 的属性才拷贝
for (let key in object) {
if (object.hasOwnProperty(key)) {
newObject[key] = object[key];
}
}
return newObject;
}
// 深拷贝的实现;
function deepCopy(object) {
if (!object || typeof object !== "object") return;
let newObject = Array.isArray(object) ? [] : {};
for (let key in object) {
if (object.hasOwnProperty(key)) {
newObject[key] =
typeof object[key] === "object" ? deepCopy(object[key]) : object[key];
}
}
return newObject;
}
浅拷贝指的是将一个对象的属性值复制到另一个对象,如果有的属性的值为引用类型的话,那么会将这个引用的地址复制给对象,因此两个对象会有同一个引用类型的引用。浅拷贝可以使用 Object.assign 和展开运算符来实现。
深拷贝相对浅拷贝而言,如果遇到属性值为引用类型的时候,它新建一个引用类型并将对应的值复制给它,因此对象获得的一个新的引用类型而不是一个原有类型的引用。深拷贝对于一些对象可以使用 JSON 的两个函数来实现,但是由于 JSON 的对象格式比 js 的对象格式更加严格,所以如果属性值里边出现函数或者 Symbol 类型的值时,会转换失败。
17. 手写 call、apply 及 bind 函数
TIP
// call函数实现
Function.prototype.myCall = function(context) {
// 判断调用对象
if (typeof this !== "function") {
console.error("type error");
}
// 获取参数
let args = [...arguments].slice(1),
result = null;
// 判断 context 是否传入,如果未传入则设置为 window
context = context || window;
// 将调用函数设为对象的方法
context.fn = this;
// 调用函数
result = context.fn(...args);
// 将属性删除
delete context.fn;
return result;
};
// apply 函数实现
Function.prototype.myApply = function(context) {
// 判断调用对象是否为函数
if (typeof this !== "function") {
throw new TypeError("Error");
}
let result = null;
// 判断 context 是否存在,如果未传入则为 window
context = context || window;
// 将函数设为对象的方法
context.fn = this;
// 调用方法
if (arguments[1]) {
result = context.fn(...arguments[1]);
} else {
result = context.fn();
}
// 将属性删除
delete context.fn;
return result;
};
// bind 函数实现
Function.prototype.myBind = function(context) {
// 判断调用对象是否为函数
if (typeof this !== "function") {
throw new TypeError("Error");
}
// 获取参数
var args = [...arguments].slice(1),
fn = this;
return function Fn() {
// 根据调用方式,传入不同绑定值
return fn.apply(
this instanceof Fn ? this : context,
args.concat(...arguments)
);
};
};
call 函数的实现步骤:
- 判断调用对象是否为函数,即使我们是定义在函数的原型上的,但是可能出现使用 call 等方式调用的情况。
- 判断传入上下文对象是否存在,如果不存在,则设置为 window 。
- 处理传入的参数,截取第一个参数后的所有参数。
- 将函数作为上下文对象的一个属性。
- 使用上下文对象来调用这个方法,并保存返回结果。
- 删除刚才新增的属性。
- 返回结果。
apply 函数的实现步骤:
- 判断调用对象是否为函数,即使我们是定义在函数的原型上的,但是可能出现使用 call 等方式调用的情况。
- 判断传入上下文对象是否存在,如果不存在,则设置为 window 。
- 将函数作为上下文对象的一个属性。
- 判断参数值是否传入
- 使用上下文对象来调用这个方法,并保存返回结果。
- 删除刚才新增的属性
- 返回结果
bind 函数的实现步骤:
- 判断调用对象是否为函数,即使我们是定义在函数的原型上的,但是可能出现使用 call 等方式调用的情况。
- 保存当前函数的引用,获取其余传入参数值。
- 创建一个函数返回
- 函数内部使用 apply 来绑定函数调用,需要判断函数作为构造函数的情况,这个时候需要传入当前函数的 this 给 apply 调用,其余情况都传入指定的上下文对象。
18. toString() 和 valueOf() 区别
TIP
valueOf 偏向于运算,toString 偏向于显示 valueOf 除了 date 会返回 时间戳,其它都会返回 数据本身
19. 123.toString() 报错 和 123..toString()
TIP
原来javascript采用 IEEE 754 的规范 双精度数字,js中只有一种数字类型:基于 IEEE 754 标准的双精度。他并没有为整数给出一种特定的类型,所以 所有的数字都是小数
123.toString() 等价于 123.0toString(),所以这条语句会报错 因此 123..toString() 123 .toString() (123).toString() 才会有正确的返回值
20. 事件循环机制(微任务和宏任务) Event Loop
详情链接参考:面试必问之 JS 事件循环(Event Loop)
事件循环是通过任务队列的机制来进行协调的。
- js 分为同步任务和异步任务
- 同步任务都在主线程上执行,形成一个执行栈
- 主线程之外,事件触发线程管理着一个任务队列,只要异步任务有了运行结果,就在任务队列之中放置一个事件
- 一旦执行栈中的所有同步任务执行完毕,系统就会读取任务队列,将可运行的异步任务添加到可执行栈中,开始执行
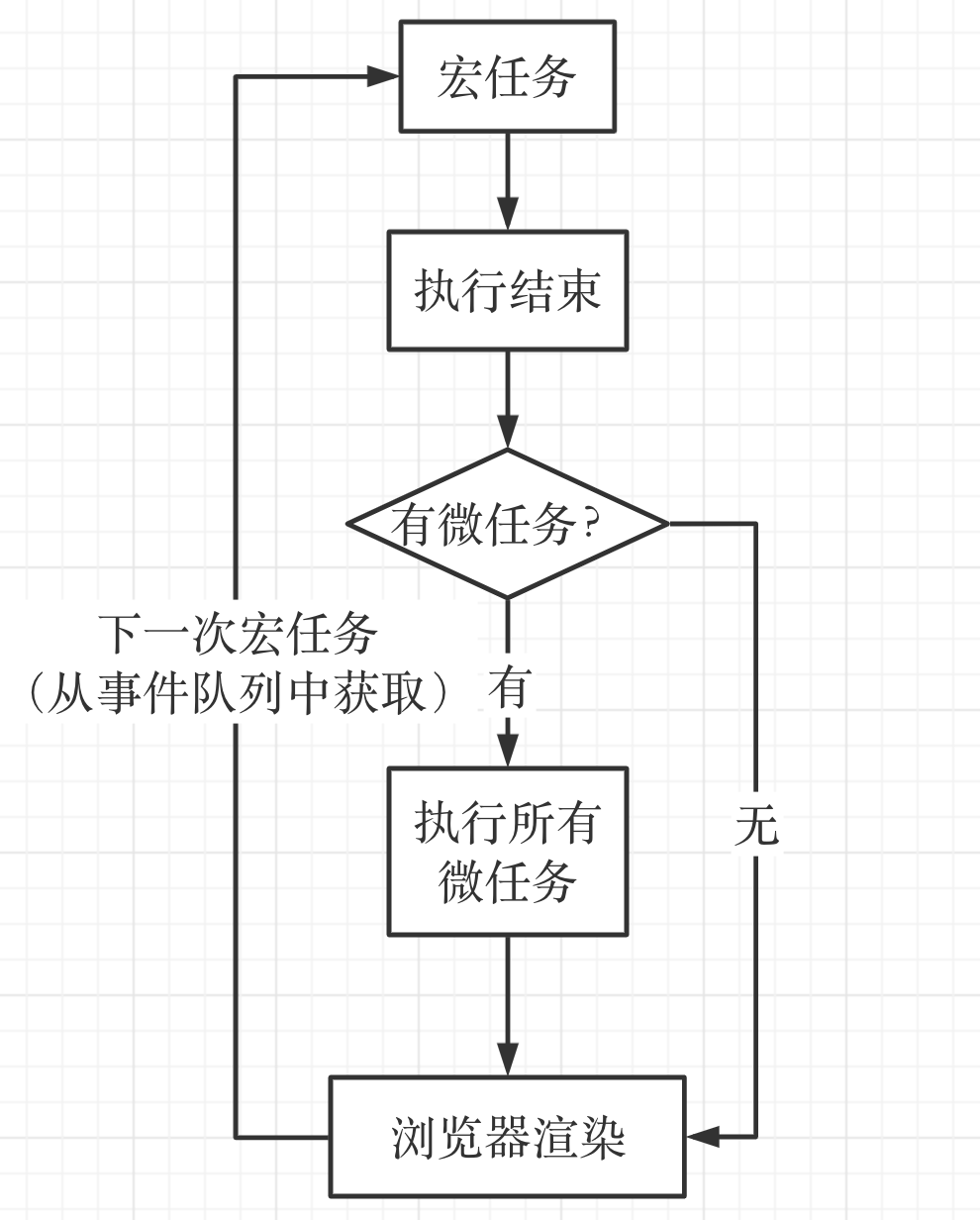
宏任务
(macro)task,可以理解是每次执行栈执行的代码就是一个宏任务(包括每次从事件队列中获取一个事件回调并放到执行栈中执行)
(macro)task => 渲染 => (macro)task => ...
包含:
- script(整体代码)
- setTimeout
- setInterval
- I/O
- UI交互事件
- postMessage
- MessageChannel
- setImmediate(Node 环境)
微任务
microtask,可以理解是在当前task执行结束后立即执行的任务。也就是说,在当前task 任务后,下一个task之前,也在渲染之前
所以它的响应速度相比 setTimeout(setTimeout 是 task)会更快,因为无需等渲染。也就是说,在某一个宏任务执行完后,就会将在它执行期间产生的所有微任务都执行完毕(在渲染前)
包含:
- Promise.then
- Object.observe
- MutationObserver
- process.nextTick(Node 环境)
运行机制
在事件循环中,每进行一次循环操作称为 tick,每一次 tick的任务处理模型都是比较复杂的,但关键步骤如下:
- 执行一个宏任务(栈中没有就从事件队列中获取)
- 执行过程中如果遇到微任务,就将它添加到微任务的任务队列中
- 宏任务执行完毕后,立即执行当前微任务队列中的所有微任务(依次执行)
- 当前宏任务执行完毕,开始检查渲染,然后GUI线程接管渲染
- 渲染完毕后,JS线程继续接管,开始下一个宏任务(从事件队列中获取)